Use Case
- Orcrist
Overview
Our use case consists of an enterprise which features the following systems:
Customer Master
A party-type model which serves as our customer master. Here is the logical model
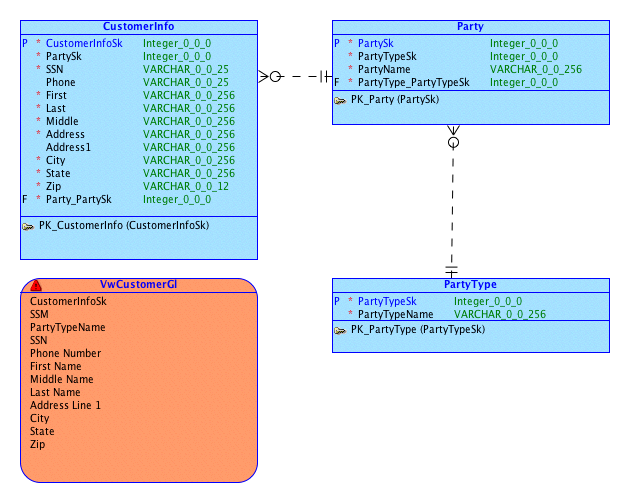
Here is the first Webcast, showing how to build a testable Customer Master database schema. Here is the completed customer master in our git repository.
Product Master
An obfuscated, very old-school database probably inherited from a multi-valued or other non-relational database system.

Here is our data dictionary:
| Column | Meaning |
|---|---|
| PRSEQ | The identifier for the record |
PRSPT | The textual description of the product. After meeting with the business, no-one seems to remember what the name means. |
| PRADT | Product activation date |
| PRRDT | Product Retirement date |
The completed schema project is located in our product master git repository.
Transactional Order Processing
An OLTP schema designed to efficiently handle customer orders.
Data Warehouse
A dimensional model combining a Slowly Changing Dimensions type-X view of our conformed Customer and Product dimensions and an order fact table.
We aren't going to concern ourselves with any real-world data - just what we need for testing.
This example won't be overly complicated but will hopefully feature many of the elements present in a real-world ETL / data warehousing environment. In order to build out this architecture, we will need to focus on the following components:
* Testable, source-controlled schemas for all data sources.
* ETL test projects
When we are done, we will have several projects built which will build our warehouse and can be used to drive true Test Driven Development and can be built in our continuous integration server to help us maintain a view of the health of our warehouse. Things we will intentionally not consider:
* Which continuous integration server is better. We use Hudson, but acknowledge that there are a lot of them that do the job just fine.
* Which version of Maven is better. We use version 3+ and don't support 2.
* Whether ant or maven is better. Both can be awesome or suck badly. Maven gives us some key features like transitive dependencies which we don't want to recreate.
* Which ETL tool is better. We demonstrate Informatica.
* The best way to write ETL code. We give samples but you can dislike them without bothering us.
* Which database is the best. There are a lot of good ones, but we need SqlServer support to be first rate since all of our projects have dependencies on it. Our goal is to support Oracle, DB2, MySQL, PostGreSQL, etc, equally - but that takes a lot of time and testing and we haven't had to do it yet.
We really want to focus on the test driven nature of the work and will spend most of our time discussing that. I am open to questions about any of the above topics directly however.
Any questions can be sent to bradleysmithllc@gmail.com.